
We are nearing the end of 2025 and I want to take the time to look back on our infrastructure design that's been in the making. We are nearly one full year live in production with our fra1 location, so this might as well be the perfect time to have a look back at our decisions, upgrades, and other changes we made.
Our infrastructure is constantly evolving, so this post might be outdated by now. Have a look around the blog to find newer posts.
Highlights of 2025
- Deployment of two production servers in Frankfurt (
fra1-1andfra1-2) - Deployment of a production server in Hamburg (
ham1-1) - Validation phase at Hetzner and discovery of PBS scaling limitations
- Introduction of the ingress proxy for intelligent routing and traffic control
- Continuous hardware refinements and data migration optimizations
Hetzner Validation Phase
Tested SX-Server with high-capacity HDDs. Discovered PBS scaling limitations with rising CPU load at 400+ datastores.
fra1-1 Deployed
First production server in Frankfurt. 2x SSDs boot, 8x 16TB HDDs, 2x SSDs metadata cache. ~90TB usable.
Ingress Proxy Go-Live
HAProxy-based routing with Lua scripts. Blocks invalid traffic, causing significant CPU drop on storage nodes.
ham1-1 Deployed
Hamburg location with 12x 28TB drives. ~250TB usable with room to double.
fra1-2 Deployed
Second Frankfurt server with 8x 18TB drives. ~100TB usable. Testing gradual capacity increases.
Start of 2025
At the beginning of 2025 we were still in a "validation" phase. Not to confuse you - we were sure that we wanted to build this project out, but finding the right hardware and software stack to offer a good cost-to-performance balance is more challenging than it might seem at first glance.
Hetzner
In our validation phase, we rented a Hetzner SX-Server, which comes with a lot of storage - exactly what we need - but quickly some concerns arose around particular performance issues.
Of course, HDDs are slow. But additionally, the way Proxmox Backup Server (from here on: PBS) works is worse for HDDs - it really benefits from fast SSDs for maintenance tasks like garbage collection and verification jobs. Since we could not add additional SSDs in the Hetzner server, we used loopback disks on the main boot SSDs to save the metadata, speeding up those jobs significantly. Of course, this is nowhere near a good solution. If the boot SSDs were to fail, all metadata and thus all backups on the host would be gone.
Another issue we observed pretty quickly was rising CPU load with the increasing number of datastores on the host system. Not a "oh yeah, totally normal" linear growth, but more like an exponential one, putting more and more strain on the CPU the more datastores were created. There are a bunch of open issues in the PBS bug tracker, but of course having hundreds of datastores on one host is not a particularly common setup, so it’s understandably not getting much attention at the moment.
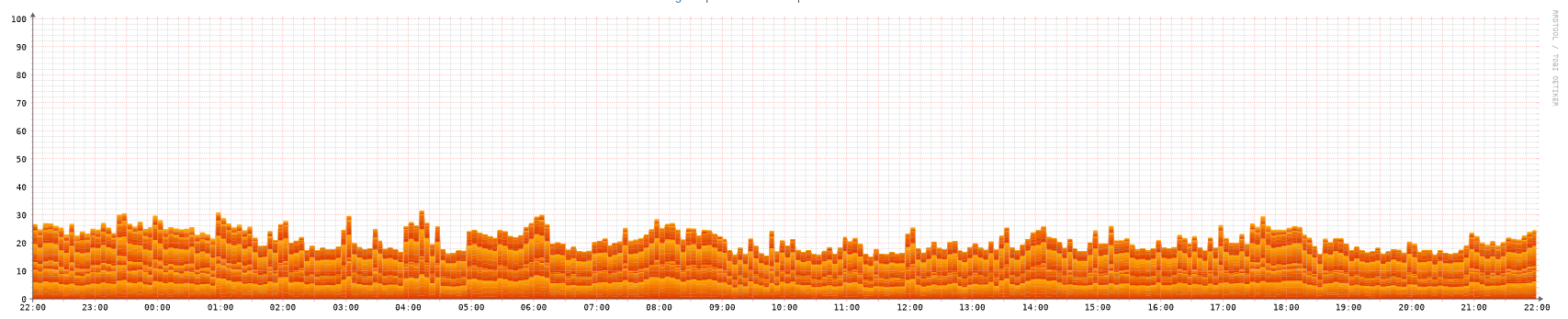
Conclusion
This left us with two main observations:
- We cannot infinitely scale the storage per host (because of rising CPU load)
- We need SSDs somewhere in the system for metadata to make garbage collection and verification faster
This meant the most basic idea was off the table: Take a 1U system, slap an external HBA inside, and connect some kind of high-capacity JBOD with very high-capacity disks to it and put some 4,000+ datastores on it. This would have totally crushed the performance of the head system, making it borderline unusable.
A JBOD would have been great because we get high storage density in a nice form factor with not much to worry about. And we can even start by populating only a few drives and grow them as needed. The head system could even hold the SSD cache, which would have been perfect.
fra1
With the learnings from the Hetzner server, we started to plan how we can scale the storage setup to have a good balance of performance and cost - for you (the customer) and us (as the provider). We landed on a pretty "normal" setup and are currently deploying mostly the same servers. BUT we are still experimenting with the new hosts we add.
fra1-1 - as the first host to physically arrive in our colocation - has 2x SSDs for boot, 8x 16TB HDDs, and 2x SSDs for metadata cache. With RAIDZ2, this gives us just shy of 90TB of usable space.
For fra1-2 (the second host at this location) we are deploying 8x 18TB drives, leaving us with around 100TB of usable space.
This way we can test changes (like increasing the raw storage capacity in this case) gradually without committing to big purchases that might not work out as expected.
ham1
But of course, we are also not perfect. The ham1-1 host has a whopping 12x 28TB drives, giving us almost 250TB in a single host - with room to grow to double that size. This is not optimal due to the aforementioned issues in PBS, but we have ways around that (kinda - continue reading).
We will obviously still maintain this location because it's great. But currently, growing the existing host is not very feasible.
ingress proxy
Why we built it
Here’s the thing - when you offer something for free, most people don't really feel obligated to do anything. When we started offering free datastores, we saw an increase in registrations and created datastores. Some of these datastores were only used to push a test backup. While this is not a problem in itself (of course, the free tier exists to try out the service), we are actively removing datastores that are in the free tier and have not been used in 14 days to keep space for other users who want to try it out.
The problem is, most of the time, people do not remove the datastore from their infrastructure, meaning there are a lot of requests coming to datastores that simply no longer exist. This puts even more load on the systems (yes, more than valid requests).
How the ingress proxy works
At the beginning of September, we started to route traffic over our so-called "ingress proxy" (hostname: fra1-ingress.pbs-host.de). This ingress proxy allows us to route traffic to corresponding downstream storage hosts and - more importantly - block invalid traffic. This is done by using HAProxy with custom Lua scripts to fetch data from a few caches.
The ingress proxy parses out headers and looks up the correct downstream server where a datastore is located. If we cannot find the datastore, we can simply return a 401 on the ingress proxy, saving expensive compute time on the storage nodes, which caused a significant drop in CPU usage.

Infrastructure integration
Since we changed the DNS entries for the explicit hosts to point to the IP of the ingress proxy, we also do hostname-based routing. For SSH we use a program called sshpiper to do the exact same things we do in HAProxy, but on an SSH level.
Additional advantages
Since we terminate each and every request at the same point (the ingress proxy), we can do some additional stuff that would not be possible using PBS alone. This includes ACLs, where you can whitelist IPs that are allowed to communicate with the datastore. If the IP requesting information is not on the whitelist, the request gets blocked.
Thanks to HAProxy, we can also use the built-in traffic shaping to limit the possible speed at which users can push backups. Since most of the time, end users are using a residential internet connection, this is not even a problem for them. It enables us to do better bandwidth planning and makes sure one user cannot saturate the whole bandwidth, leaving other customers stuck with nothing.
Current state (End of 2025)
Now we have deployed the fra1-2 server, our own hardware for the ingress gateway, and are looking forward to the go-live of those two.
From the pictures, you can see thick QSFP+ cables - those are interconnects between the storage and ingress hosts, which we can use for normal proxy traffic and to move data between storage hosts quickly.

The fast movement of data is important because we sometimes need to rebalance data between storage hosts. If one datastore grows too big for the current host, we move it to another server where it can grow more. To facilitate that, we built a complete migration process using zfs send/zfs receive to write the data from one dataset to another. During this time, the customer cannot reach their datastore (to avoid split-brain situations), so we want to make it as fast as possible.
And with the ingress proxy, the customer does not even need to update anything in their setup - just calculate an hour or two for the data move, and it’s all complete.
Future Outlook
We are preparing several expansions for early 2026. These include scaling the ingress layer with dedicated caching, adding SSD-driven metadata nodes, and continuing refinement of the data migration automation pipeline. We are also exploring a multi-region setup to improve latency and resilience for users outside Germany.
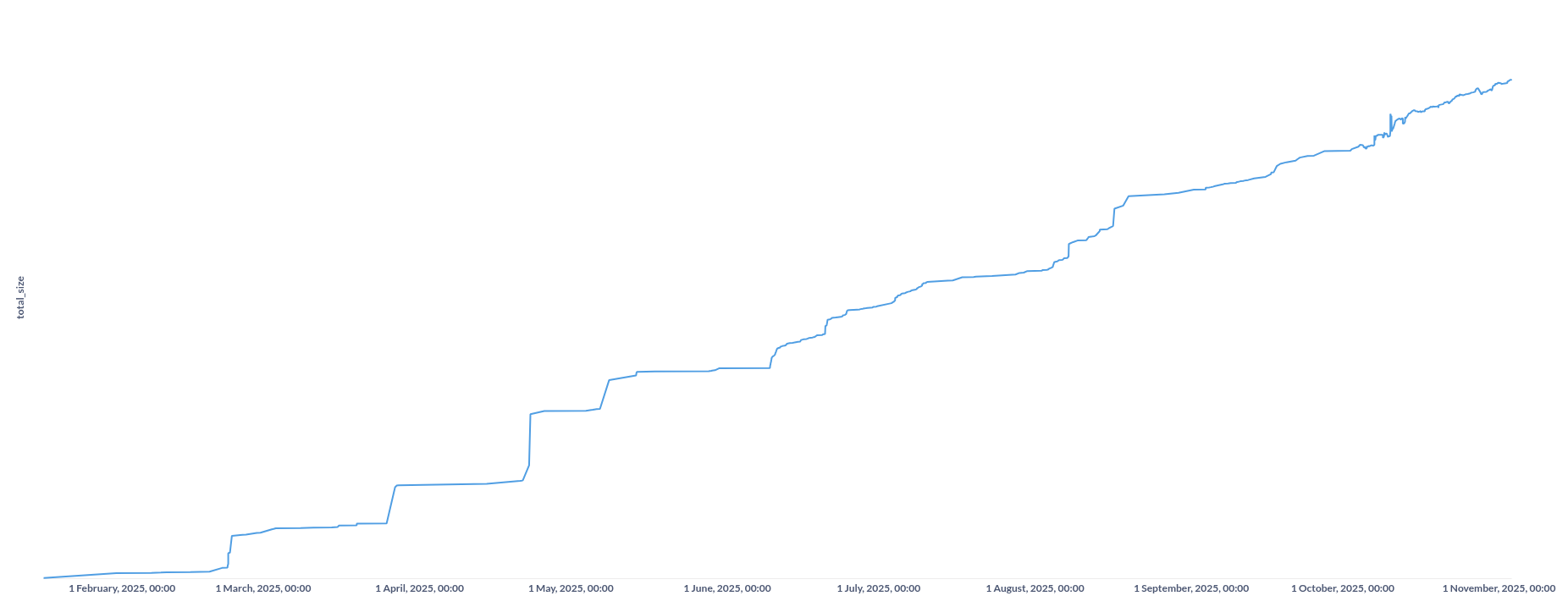
Conclusion
So we have learned a lot. From the initial go-live with the mindset "It cannot be that hard to run a hosted PBS" to "Well, actually, it's a bit more complicated to deliver a reliable cloud-storage platform" - but we are on a good track. Running a service is easy; scaling is challenging. BUT we are optimistic to tackle any challenge that comes our way!
While this is of course only a snapshot of the current state, we are looking forward to the software and hardware expansions next year. We have lots of things planned - some are already on the roadmap - so we will keep you posted on that.
I want to personally shout-out everyone using us, be it free-tier or paid-tier, you guys make this all possible, thank you very very much! Our growth has been extensive and broke our best-case calculations by a margin, so we are very grateful to have each and everyone of you on board!
If you like this post and want more of these in-depth technical posts, please share this on the social networks of your choice. If you want to talk, reach out to me at bennet@remote-backups.com!
Shoutouts
Thanks to Moritz from Nerdscave Hosting (our colocation provider in Frankfurt) for the sleepless nights upgrading and refining the infrastructure together with us (and the cool pictures, of course). He's our man on scene, thanks! Also, a big thanks to Lars & the people at NMMN (our colocation provider in Hamburg). Rock-solid network and very competent staff!


